Aaron Richter, PhD
data scientist // data engineer
I'm passionate about all things data! I am happiest when optimizing business processes using data pipelines and analytics, or teaching a room full of data nerds about a cool algorithm. I write code for production and make sure research is reproducible. I'm a technical leader to a team of data professionals and hold a PhD in machine learning for healthcare applications.
Want to see more? Check out my projects!
What I Do
- data engineering
- machine learning
- data analysis
- programming
- tech leadership
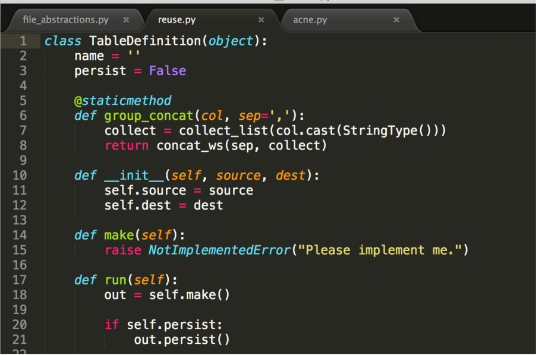
- Pipelines
- ETL
- Data quality
- Cloud computing
- Spark Certified Developer
Spark
Expert
Dask
Fluent
Airflow
Fluent
Prefect
Fluent
AWS
Fluent
Databricks
Expert
Unix
Fluent
- Classification
- Deep learning
- Computer vision
- Model interpretation
- Class imbalance
- High dimensionality
scikit-learn
Expert
fastai/pytorch
Dabbler
keras/tensorflow
Dabbler
caret/tidymodels
Fluent
Spark ML
Fluent
- Notebooks
- Reproducibility
- Visualization
- Storytelling
jupyter
Expert
pandas/numpy
Expert
ggplot2
Expert
tidyverse
Expert
RMarkdown
Expert
Shiny
Fluent
SQL
Expert
Excel
Expert
- Data
- Web
- Mobile
- Academic writing
Python
Expert
R
Expert
SQL
Expert
HTML/CSS
Fluent
Javascript
Fluent
Swift
Dabbler
Scala
Dabbler
LaTeX
Fluent
- Talks & tutorials
- Team development
- Talent acquisition
- Software lifecycle
- Mentorship
Speaking
Expert
Training
Fluent
Mentor
Dabbler
Release management
Fluent
Documentation
Fluent